The fpgaConvNet framework operates on an intermediate representation that describes the hardware of a mapped ML model. This component of the framework takes onnx files and creates the fpgaconvnet-ir used to generate hardware. Furthermore, the IR can also be used to generate high-level performance and resource models of the hardware. This IR is fundamental for rapid design space exploration.
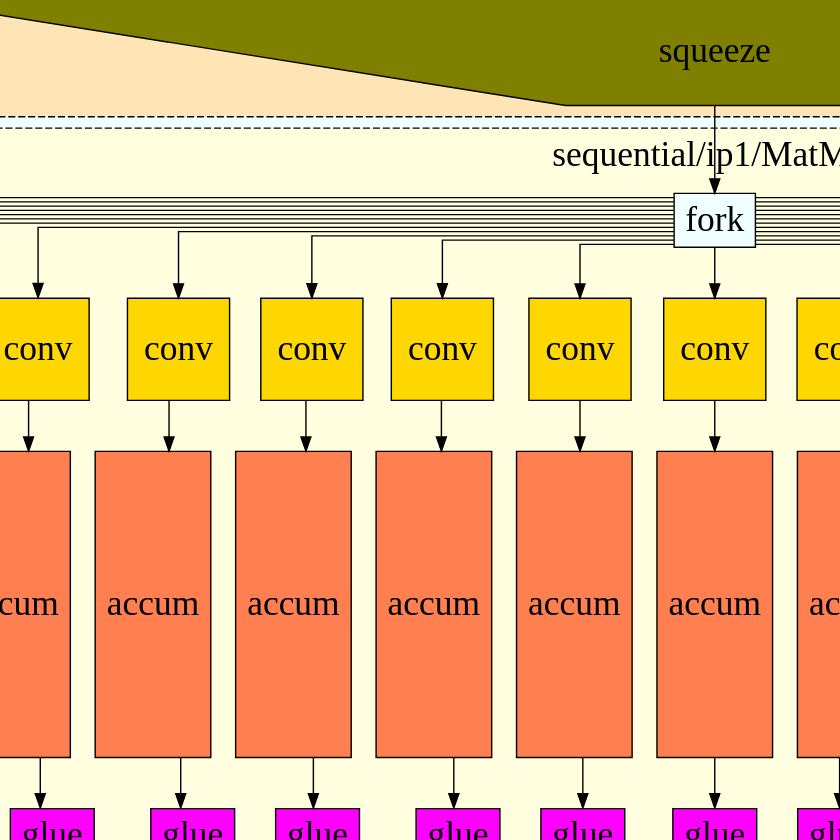
Using a configuration generated by the fpgaconvnet-model tool, the corresponding hardware can be generated by the fpgaconvnet-hls tool. This repository contains of selection of highly parametrised hardware building blocks for common CNN layers (Convolution, Pooling, ReLU, etc). A dataflow architecture is generated by instantiating and connecting these building blocks together based on the configuration file.
The design space of streaming architectures are immense, with even seemingly small networks such as LeNet having 1013 possible design points, taking 89 centuries to evaluate every single one. The fpgaConvNet toolflow allows designers to automate the design point selection process, using optimisation solvers tailored to the problem. SAMO is a framework that generalises the optimisation problem across streaming architectures, providing a toolflow for both FINN and HLS4ML. the fpgaconvnet-optimiser project is specialised to the fpgaConvNet architecture, finding even better design points.
